20. 🔬 Тестирование работоспособности Apache Atlas
2021-12-06
После подключения Apache Atlas’а к Hadoop’у мы должны удостовериться в работоспособности приложения.
1. Проверка получения информации из Hive
1.1. На машине с ролью HDFS Gateway, в своём домашнем каталоге создаём csv-файл и загружаем в HDFS:
TESTFILENAME="atlas25.csv"
cat << EOF > ${TESTFILENAME}
1,Hive Hook
2,HBase Hook
3,Spark Hook
EOF
hdfs dfs -put ${TESTFILENAME}
1.2. Есть вероятность что аккаунт hive, которого чуть позже заставим импортировать данные из файла в таблицу, не имеет прав на домашний каталог + созданный файл, поэтому выдаём права:
HDFSHOMEDIR="/user/dmr"
hdfs dfs -setfacl -m user:hive:rwx ${HDFSHOMEDIR}
hdfs dfs -setfacl -m user:hive:rw ${TESTFILENAME}
1.3. На машине с ролью ‘Hive Gateway’ подключаемся к Apache Hive с помощью утилиты beeline :
$ beeline
beeline> !connect jdbc:hive2://dev-aux110p.test2.lan:10000/;ssl=true;sslTrustStore=/usr/java/jdk1.8.0_181-cloudera/jre/lib/security/jssecacerts
Enter username for jdbc:hive2://dev-aux110p.test2.lan:10000/: dmr
Enter password for jdbc:hive2://dev-aux110p.test2.lan:10000/: ******************
0: jdbc:hive2://dev-aux110p.test2.lan:100> show databases;
+-------------------+
| database_name |
+-------------------+
| michael_test |
| default |
| dmrtest |
+-------------------+
1.4. Выполняем создание новой базы данных:
0: jdbc:hive2://dev-aux110p.test2.lan:100> create database atlas25;
1.5. Выполняем создание Hive-таблицы:
0: jdbc:hive2://dev-aux110p.test2.lan:100> CREATE TABLE IF NOT EXISTS atlas25.atlas25 (Num int, HookName String)
COMMENT 'Atlas function check'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
1.6. Выполняем импорт данных из файла в созданную ранее таблицу:
0: jdbc:hive2://dev-aux110p.test2.lan:100> LOAD DATA INPATH 'atlas25.csv' OVERWRITE INTO TABLE atlas25.atlas25;
1.7. В Apache Atlas’е выполняем поиск сущностей по ключевому слову atlas25 и наблюдаем результат:
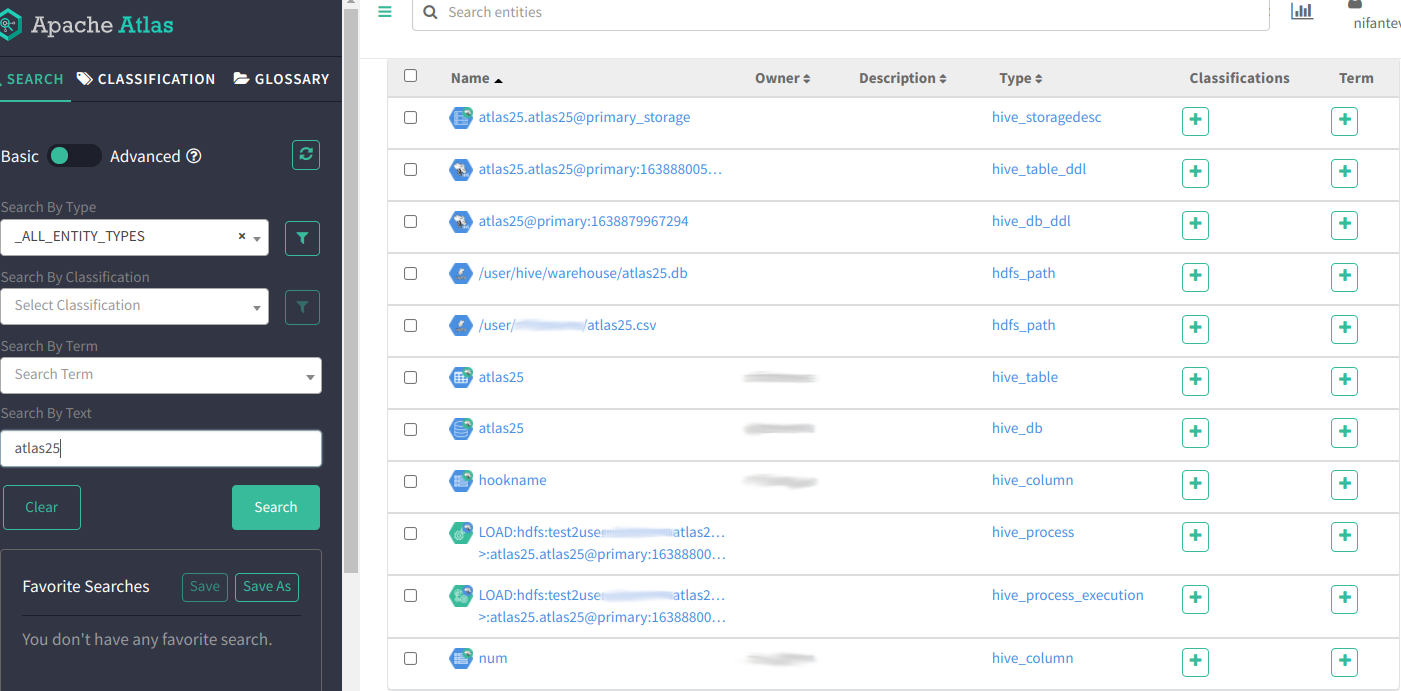
1.8. Щёлкнув по ссылке на ‘atlas25’ с типом ‘hive_table’, на открышейся странице, во вкладке Lineage, наблюдаем “линейку”:
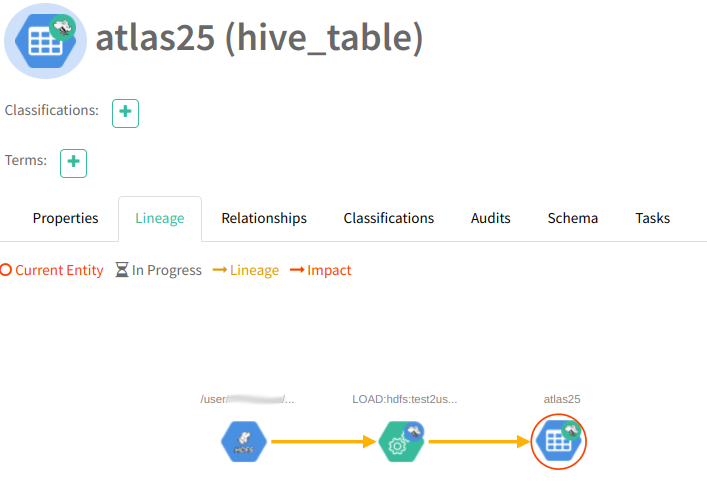
1.9. После успешного выполнения вышеуказанных упражнений можно сказать, что информация из Hive в Atlas поступает.
2. Проверка получения информации из HBase
2.1. На машине с ролью HDFS Gateway, в своём домашнем каталоге создаём csv-файл и загружаем в HDFS:
TESTFILENAME="atlas26.csv"
cat << EOF > ${TESTFILENAME}
1,Hive Hook
2,HBase Hook
3,Spark Hook
EOF
hdfs dfs -put ${TESTFILENAME}
2.2. На машине с ролью ‘HBase Gateway’ получаем kerberos-тикет и создаём HBase-таблицу ‘atlas26’:
kinit dmr
echo "create 'atlas26', 'n', 'hook'" | hbase shell
2.3. Импортируем данные из файла atlas26.csv в созданную HBase-таблицу:
$ hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.separator=',' \
-Dimporttsv.columns=HBASE_ROW_KEY,n,hook atlas26 /user/dmr/atlas26.csv
2.4. Проверяем содержимое таблицы (впрочем это не обязательно):
$ echo "scan 'atlas26'" | hbase shell
...
scan 'atlas26'
ROW COLUMN+CELL
1 column=n:, timestamp=1638889043225, value=Hive Hook
2 column=n:, timestamp=1638889043225, value=HBase Hook
3 column=n:, timestamp=1638889043225, value=Spark Hook
3 row(s)
Took 0.7221 seconds
2.5. В Apache Atlas’е выполняем поиск сущностей по ключевому слову atlas26 и наблюдаем результат:
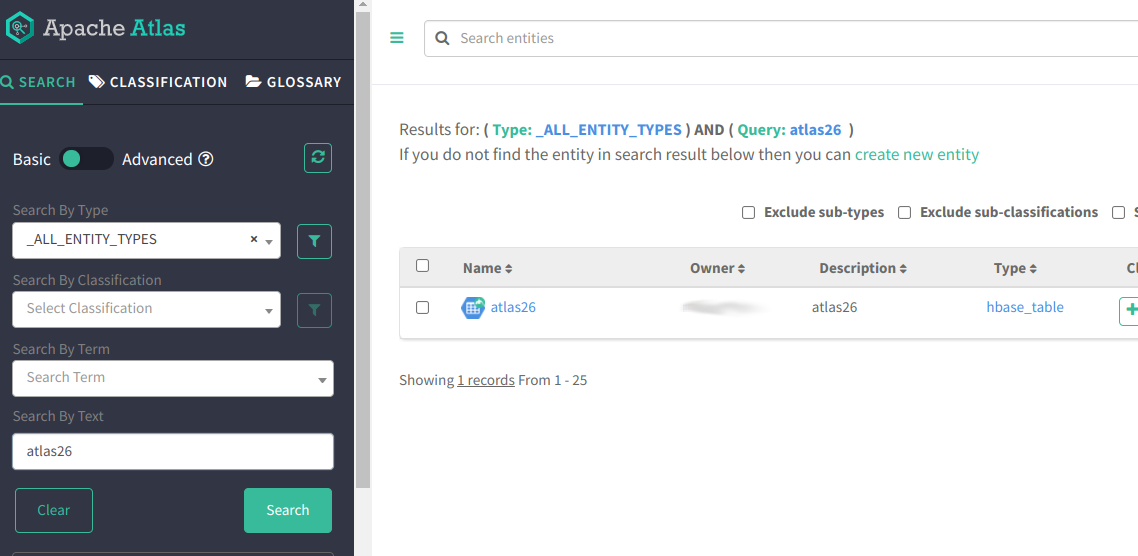
2.6. В отличии от данных из Hive, HBase не может предоставить Атласу файл-источник данных, поэтому “Линейка” останется пуста:
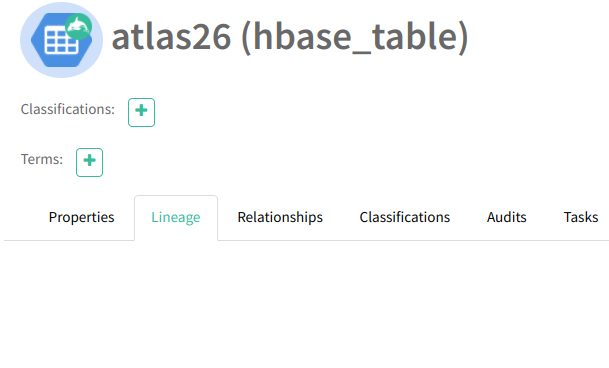
2.7. В любом случае, в случае успешного прохождения этого теста, можно утверждать, что данные из HBase в Apache Atlas поступают.
3. Проверка получения информации из Spark
При случае дописать.